There’s a growing sentiment out there with all the wonderful things happening in artificial intelligence, machine learning, and data science that these technologies are ready to solve all the things (including how to kill all humans). The reality is there are still a bunch of significant hurdles between us and the AI dystopia/utopia. One big one that is the main impetus behind my research is the disconnect between the statistical foundations of machine learning and how real data works.
Machine learning technology is built on a foundation of formal theory. Statistical ideas, computer science algorithms, and information-theoretic concepts integrate to yield practical methods that analyze large, noisy data sets to train actionable and predictive models. The power of these methods has caused many to realize the value of data.
Yet, as data collection accelerates, weaknesses of existing machine learning methods reveal themselves. The nature of larger-scale data collection violates key assumptions in the foundation that made machine learning so effective. Most notably, statistical independence is no longer achievable with large-scale data. Data is being collected from highly interacting, entangled, complex systems. Human data describes people interacting in a single global social network; ecological data represents measurements of organisms inhabiting complex, shared ecosystems; and medical data measures the interconnected, biological systems that govern health.
Origins in Experimental Statistics
The concept of statistical independence is a natural fit for laboratory experimentation. In laboratory experiments, scientists test hypotheses by running repeated experiments in closed environments. By design, the measurements taken during each experiment are independent. Because one experiment can’t affect another’s result, classical statistics can confidently quantify the effects of factors in the experiment, even in the presence of randomness.
For example, a typical pre-clinical laboratory drug trial would use a population of animal subjects, administering a drug to part of the population and giving no treatment to a separate control subpopulation. The two subpopulations would be managed to ensure that confounding factors, such as genetics, are equally distributed. The individual subjects would be kept separated in isolated environments. By preventing subjects from interacting with each other, any observations of the drug’s effects can be considered fully independent samples, and classical statistics would enable comparison of effects with quickly converging confidence intervals.
In modern data, measurements are taken from “the wild.” Modern data is analogous to a version of the experiment where the animal subjects interact, sharing food, contact, and communication. Generally, data collections describe large populations of interacting parts, with each measurement related through correlated paths. As modern data collection technology becomes faster and cheaper, the data necessarily becomes increasingly interdependent.
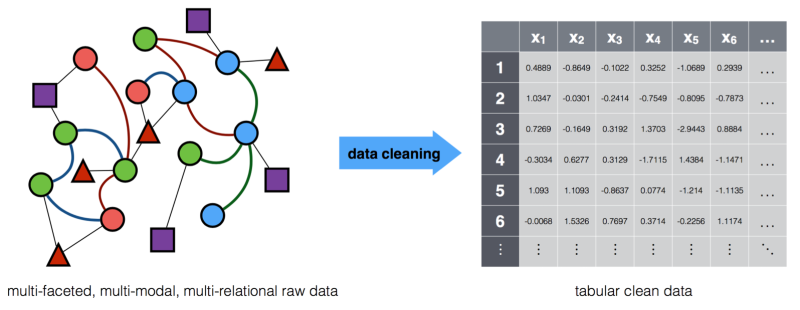
Illustration of the data cleaning task. A common view of complex data is that it can be “cleaned” to fit the structure expected in classical statistics and machine learning methods. But this cleaning typically decimates the nuanced information present in data from real-world, complex phenomena.
The Myth of Clean Data
It’s tempting to interpret these nuances of real-world data to be simply nuisances. One may attempt to convince oneself that the discrepancy between classical statistical methods and real data can be remedied by data cleaning. Data cleaning—a key skill in modern data analysis—involves taking raw data, processing it to remove spurious outliers, undesired dependencies, and biases created by interacting measurements, then performing supposedly clean analysis on the supposedly clean data.
The clean data concept encourages deliberate omission of information, introduction of unjustified assumptions, and fabrication of facts, to turn real-world data, with all its complexities, into rectangular tables of independent samples. These manipulations undo many of the virtues of data-driven thinking.
The perception that machine learning methods require such destructive preprocessing is a major failure in the technology transfer from machine learning research to practical application. And the reasons for this failure manifest in the various costs associated with more nuanced machine learning methods. Methods that can reason about interdependent data require more computational cost—the amount of computer time and energy needed to learn, reason, and predict using these methods—and cognitive cost—the amount of expertise necessary to apply, understand, and interpret these methods.
“Conclusion”
So what’s the point of my arguments here? I’m not super certain, but here are a few possible takeaway points:
- Big data is complex data. As we go out and collect more data from a finite world, we’re necessarily going to start collecting more and more interdependent data. Back when we had hundreds of people in our databases, it was plausible that none of our data examples were socially connected. But when our databases are significant fractions of the world population, we are much farther away from the controlled samples of good laboratory science. This means…
- Data science as it’s currently practiced is essentially bad science. When we take a biased, dependent population of samples and try to generalize a conclusion from it, we need to be fully aware of how flawed our study is. That doesn’t mean things we discover using data analytics aren’t useful, but they need to be understood through the lens of the bias and complex dependencies present in the training data.
- Computational methods should be aware of, and take advantage of, known dependencies. Some subfields of data mining and machine learning address this, like structured output learning, graph mining, relational learning, and more. But there is a lot of research progress needed. The data we’re mostly interested in nowadays comes from complex phenomena, which means we have to pay for accurate modeling with a little computational and cognitive complexity. How we manage that is a big open problem.


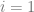

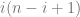

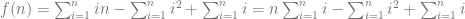
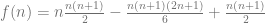

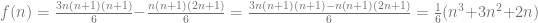

 ,
, and
and 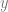 are vectors, functions
are vectors, functions 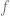 and
and 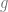 map from their respective vector spaces to scalar outputs, and
map from their respective vector spaces to scalar outputs, and 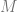 is a matrix. Assume that
is a matrix. Assume that  .
. ,
, . We can then consider the optimization
. We can then consider the optimization .
.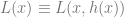 is
is .
. , which is clearly a function that depends on
, which is clearly a function that depends on  with a constraint $Ax = b$, you can form the Lagrangian problem
with a constraint $Ax = b$, you can form the Lagrangian problem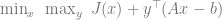 ,
, ,
,  , and
, and  . This general form also arises in structured prediction, for example when the inner maximization is the separation oracle of a structured support vector machine or the variational form of inference in a Markov random field.
. This general form also arises in structured prediction, for example when the inner maximization is the separation oracle of a structured support vector machine or the variational form of inference in a Markov random field. .
.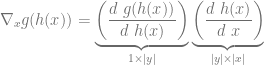 . (I’m probably botching the transposes here.)
. (I’m probably botching the transposes here.)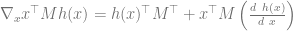 .
. , we know that its gradient wrt
, we know that its gradient wrt  ,
, , and
, and  .
. .
.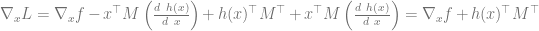 .
. .
.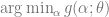 ,
,
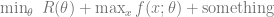
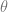 and maximizing over the predictions
and maximizing over the predictions  .
.